Good Seed Makes a Good Crop
Let's get deep into the world of randomness, shall we? Into the randomness that governs the diffusion process and the wonders of controlled randomness. This journey will be a comprehensive exploration of how the tiny seeds of noise grow into the lush, vibrant gardens of generated images. https://arxiv.org/abs/2405.14828
Introduction: The Seed of the Matter
The Diffusion process or I should say the reverse diffusion process, behind every generative AI model, capable of transforming textual descriptions into detailed visual representations like Stable Diffusion 2.0 or SDXL Turbo, essentially just refines random noise into coherent images and at the heart of this process lies the `seed` a seemingly insignificant number that determines the initial state of the latents and subsequently influences the entire generative trajectory
The Diffusion Process: A Sparse Overview
! There are very good guides on how diffusion works online this is just a sparse introduction to the diffusion process to build up the notion !
The diffusion process is an iterative mechanism that converts random noise into an image. This process can be broadly divided into two stages: forward diffusion and reverse diffusion. Let's delve into these stages to understand their technical intricacies.
Forward Diffusion: Adding Noise
The forward diffusion process gradually corrupts an image by adding Gaussian noise over several steps. Mathematically, it is described by the following equation:
\(q(x_t \mid x_{t-1}) = \mathcal{N}(x_t; (1 - \beta_t) x_{t-1}, \beta_t I)\)
- \(x_t\) represents the noisy latent variable at timestep \(t\).
- \(\beta_t\) is the variance schedule, controlling the amount of noise added at each step.
- \(\mathcal{N}\) denotes a Gaussian distribution.
Over time, the image is transformed into pure noise, which serves as the starting point for the reverse diffusion process.
Reverse Diffusion: Removing Noise
The reverse diffusion process, guided by a pre-trained model, aims to denoise the noisy latent variables step-by-step, eventually reconstructing a high-quality image. This is expressed as:
\(p_\theta(x_{t-1} \mid x_t, \mathbf{s}) = \mathcal{N}(x_{t-1}; \mu_\theta(x_t, t, \mathbf{s}), \Sigma_\theta(x_t, t, \mathbf{s}))\) where:
- \(\mu_\theta(x_t, t, \mathbf{s})\) is the predicted mean, influenced by the current state \(x_t\), timestep \(t\), and the seed \(\mathbf{s}\).
- \(\Sigma_\theta(x_t, t, \mathbf{s})\) is the predicted variance.
- \(\mathbf{s}\) is the seed, which ensures the process is stochastic but repeatable.
[Appendix A]
Seeds: The Architects of Randomness
Moving on to the core focus of the this blog: Seeds play a crucial role in this process. Each seed initializes the random number generator that produces the initial noise and the noise added at each reverse diffusion step. Consequently, the choice of seed can lead to vastly different generated images even for the same textual description
Exploring the Impact of Seeds
To illustrate the profound impact of seeds, let's consider two examples:
- Best Seed (FID [Appendix B]: 21.60): Seed 469
- Worst Seed (FID: 31.97): Seed 696

Seed and Intermediate Noise
An interesting facet of the seed's influence is its effect on intermediate noise levels during the reverse diffusion process. Our experiments and the experiments from the paper revealed that while the initial noise predominantly determines the final image, the noise added at each step, controlled by the seed, does not really affect the quality or has any substantial change in the final output.

we first set the seed to `i` and begin the reverse diffusion process. Then, at an intermediate timestep, we change the seed to `j` and complete the image generation process. We explore using seeds 0 and 1 for both `i` and `j`, as well as swapping the seed at early, mid, and late timesteps respectively of the reverse diffusion process. Despite these variations, we found that the initial noisy latent significantly controls the generated content, while the random noise introduced at intermediate reparameterization steps has no visible impact on the generated images
Visual Fingerprints: The Seeds' Distinguishing Marks
Each seed imprints a unique "visual fingerprint" on the generated images. The authors from the paper trained a 1,024-way classifier to predict the seed from an image with over 99.9% accuracy, demonstrating the distinct influence of seeds. This classifier revealed that even subtle variations in noise, dictated by the seed, result in distinguishable visual features. These findings suggest that seeds may encode unique visual features, prompting us to explore their impact across several interpretable dimensions
The authors reduced the dimensions in order to better classify the seeds according to the features which resulted in some seeds giving certain features in the output i.e. having a frame around the image even though not prompted to, having a white sky instead of a blue sky, giving a grayscaled output etc.
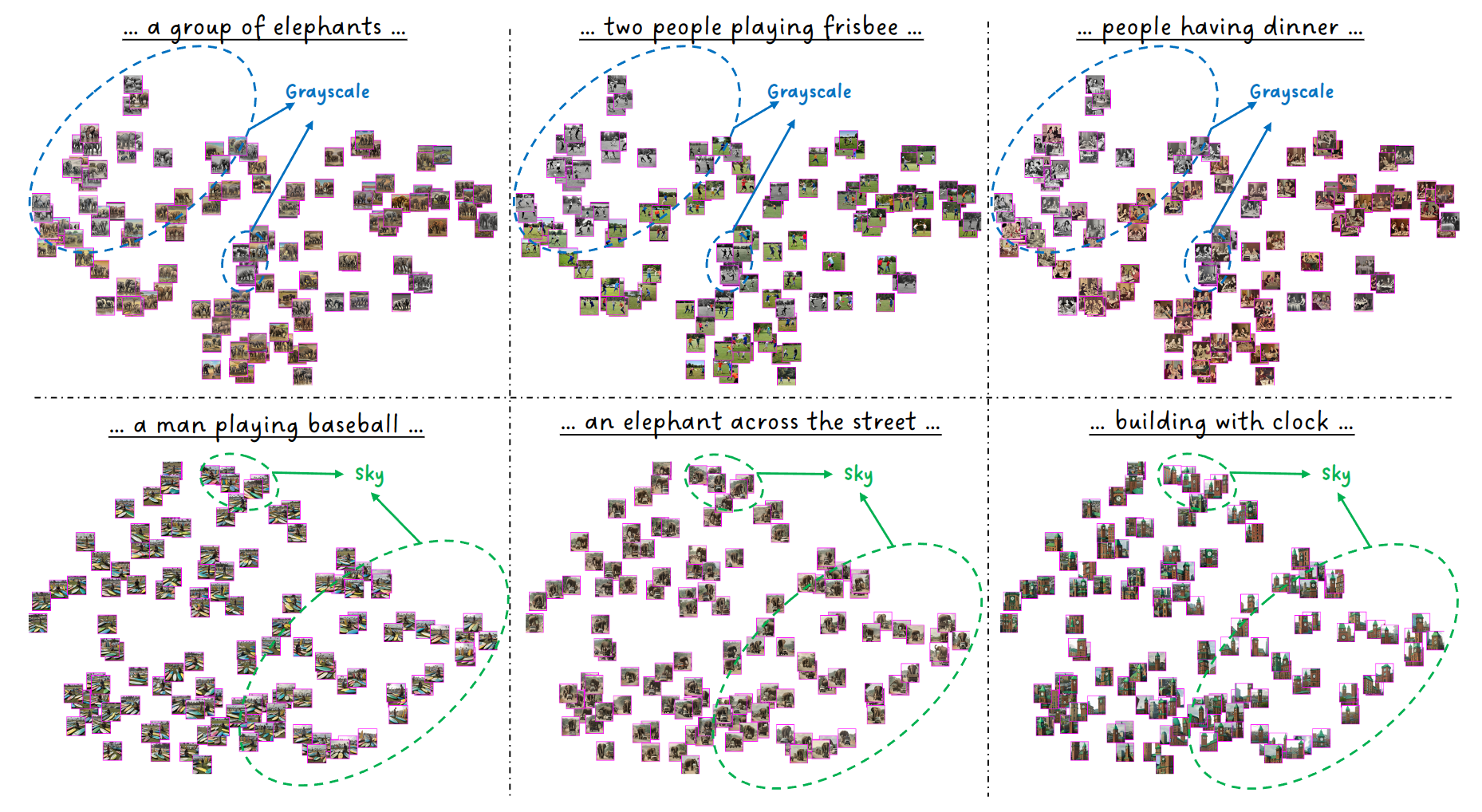
For more details and a detailed overview of all the methods and results mentioned go read the paper https://arxiv.org/abs/2405.14828
Applications: High-Fidelity Inference and Diversified Sampling
By identifying and leveraging "golden seeds," we can:
- Enhance high-fidelity inference by limiting sampling to top-K seeds, improving FID scores.
- Enable diversified sampling based on style or layout, providing users with a variety of visually distinct images.
- Improve inpainting quality by avoiding seeds that introduce unwanted text artifacts.
Conclusion: The Magic of Good Seeds
Our journey through the randomness of seeds in T2I diffusion models reveals that not all seeds are created equal. By understanding and leveraging the power of good seeds, we can push the boundaries of what’s possible in image generation. Stay tuned for more deep dives and keep those seeds planted firmly in the fertile ground of your curiosity. And remember, in the world of T2I diffusion, a good seed makes a good crop.
Appendix A : Diffusion Process Equations
The forward diffusion process: \(q(\mathbf{x}_t | \mathbf{x}_{t-1}) = \mathcal{N}(\mathbf{x}_t; \sqrt{1-\beta_t} \mathbf{x}_{t-1}, \beta_t \mathbf{I})\)
Reverse process given the seed: \(p_\theta(\mathbf{x}_{t-1} | \mathbf{x}_t, \mathbf{s}) = \mathcal{N}(\mathbf{x}_{t-1}; \mu_\theta(\mathbf{x}_t, t, \mathbf{s}), \Sigma_\theta(\mathbf{x}_t, t, \mathbf{s}))\)
where \(\mu_\theta\) and \(\Sigma_\theta\) are defined as:
\(\mu_\theta(\mathbf{x}_t, t, \mathbf{s}) = \frac{1}{\sqrt{\alpha_t}} \left( \mathbf{x}_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} \epsilon_\theta(\mathbf{x}_t, t, \mathbf{s}) \right)\)
\(\Sigma_\theta(\mathbf{x}_t, t, \mathbf{s}) = \sigma_t^2 \mathbf{I}\)
with \(\alpha_t = 1 - \beta_t\) and \(\bar{\alpha}_t = \prod_{i=1}^t \alpha_i\). The term \(\epsilon_\theta(\mathbf{x}_t, t, \mathbf{s})\) is the noise predictor, a crucial part of the denoising process influenced by the seed.
Appendix B : Fréchet Inception Distance (FID)
The FID score calculation involves the mean \(\mu\) and covariance \(\Sigma\) of the real and generated image distributions:
\(\text{FID} = || \mu_r - \mu_g ||^2 + \text{Tr}(\Sigma_r + \Sigma_g - 2(\Sigma_r \Sigma_g)^{1/2})\)
Lower FID scores indicate better quality images, as the distribution of generated images is closer to that of real images.
By leveraging these mathematical frameworks, we can fine-tune the generation process to yield visually stunning and high-quality images with the right seeds. Happy seeding!
Related Work
arXiv:2404.11120, arXiv:2404.04650, arXiv:2312.08872 and others have aimed to optimize the initial noise to produce images that better align with the text prompt, reduce visual artifacts, or achieve a desired layout