Speeding up Krea-Realtime (Part-1)

Ignore the GIF artifacts thoughout the blog
I would recommend reading Krea Realtime 14B before diving into this but if you don't want to here is a quick recap of things I find interesting from the blog. Also this blog consists of a lot of failures I encountered while speeding things up here so keep that in mind. The model was trained by distilling the Wan 2.1 14B diffusion (good move I feel WAN2.2 with all its finetuning is not as trainable) model using Self-Forcing, it delivers 11 FPS inference with just 4 sampling steps on a single NVIDIA B200 GPU over 10× larger than any prior realtime video model.
Unlike conventional diffusion video models (e.g., Wan 2.1), which denoise all frames in parallel using bidirectional attention, Krea Realtime uses a causal architecture, it generates frames sequentially, one block at a time, and never revises past outputs. This irreversible, streaming compatible structure enables true realtime interaction users can see the first frame in under a second, modify prompts mid-generation, restyle videos on-the-fly, and steer motion as it unfolds (SICK).
But converting a powerful bidirectional model into a stable autoregressive generator is nontrivial. The core challenge is exposure bias during training, most autoregressive methods condition on ground-truth frames, but at inference, they must rely on their own imperfect generations. This mismatch leads to error accumulation, minor artifacts compound across frames, causing catastrophic drift or collapse.
Krea Realtime overcomes this through Self-Forcing, a data-free distillation pipeline that trains the student model exactly as it will be used by autoregressively sampling full video sequences and aligning its output distribution with the teacher via Distribution Matching Distillation (DMD). This three-stage process includes:
- Timestep Distillation: Compresses Wan 2.1’s ~30-step sampling into 4 steps while retaining fidelity.
- Causal ODE Pretraining: Initializes the causal attention structure using block causal masks (bidirectional within frame blocks, causal across blocks) and synthetic ODE trajectories from the teacher.
- Self-Forcing DMD: Performs end-to-end autoregressive rollouts and uses score matching between two diffusion based discriminators to guide the student toward high-quality modes without real video data.
- First-frame distribution shift: The VAE encodes the first RGB frame differently (no temporal compression), causing artifacts when it’s evicted from the KV cache.
- Error propagation: Keys and values from evicted frames leave residual traces in later activations, amplifying past mistakes.
The result is a system that doesn’t just generate video it collaborates with prompt interpolation, sliding windows, and real-time feedback. But it’s not perfect. The DMD objective’s reliance on reverse KL divergence induces mode collapse, suppressing rare but valid motions (e.g., dynamic camera moves). This is a known limitation.
An Earlier Attempt at Training
it's worth reflecting on an earlier stab I took at replicating Krea Realtime's training pipeline. This was back when self-forcing has just came out though I was limited to 8xH200, I aimed to follow: starting with Causal ODE Pretraining, and finally the Self-Forcing Distribution Matching Distillation (DMD).
I generated synthetic ODE solution trajectories from the teacher. This stage completed successfully after around 6k steps for us I generated some initial video clips that showed stable causal initialization (attached below). Unfortunately, that's where things stalled. The next phase the "distillation pass" or Self-Forcing DMD was a beast it requires running four 14B models in parallel (real score, critic score, student, and EMA), autoregressively generating blocks during training to eliminate exposure bias. With massive KV caches and the need for dynamic freeing, gradient checkpointing, and FSDP sharding across 64+ H100s on Krea-realtime setup, my setup just couldn't handle it though I did some DMD-distilation but compute scarcity hit hard: OOM errors, sluggish throughput, and escalating costs forced me to shelve it before completing the full DMD run. tbh this is what got me excited about Krea's take on this, I've attached some generations from my attempt on this. Anyways let's move on the inference optimizations!


Starting off with replacing MLP layers
Krea-Realtime (WAN2.1) is built around a transformer architecture, which means lots of attention layers and multi-layer perceptrons (MLPs) While attention gets all the glory, the MLPs simple feedforward networks with linear transformations are where a substantial amount of compute happens. Here MLPs typically consist of two linear layers: one expanding the hidden size (e.g., from 5120 to 13824 features) and another contracting it back (13824 to 5120).
My first hunch was that PyTorch's default torch.nn.Linear layers, even when compiled with torch.compile, weren't fully optimized for the B200's architecture where there's a huge room to customize those GEMMs for better throughput.
So, I started by replacing all the MLP linear layers (non-attention ones) with a custom implementation called `UntunedQuackLinear` It's pretty much the same from quack with a little more quirks added to it.
My code block recursively walks through the model (just to make it simple), spots MLP-specific linear layers based on their shapes (hardcoded for Krea-Realtime's config), and swaps them with the custom version.
I ran this on the model in bf16 precision (which is not ideal but more to come later). Right off the bat, this made the model faster than the vanilla PyTorch nn.Linear (without compilation) on B200.
The UntunedQuackLinear class is a drop-in replacement for nn.Linear, but its forward method calls a custom function instead of PyTorch's built-in F.linear. The great part about QuackLinear is:
- It initializes weights and biases just like nn.Linear.
- The magic happens in linear_func, which is a custom autograd function wrapping an optimized GEMM from Quack.
The linear_func is where things get interesting. It's implemented as a PyTorch autograd. Function with custom forward and backward passes, using AMP hooks for efficiency:
- Forward Pass: Computes `out = x @ weight.T + bias` using a custom GEMM kernel. It handles type conversions and reshaping for batch efficiency.
- Backward Pass: Computes gradients for input, weights, and bias. It reuses tensors smartly to save memory and optionally fuses gradient accumulation (though I disabled that here with fuse_grad_accum=False).
- Tiling and Clustering: Breaks the matrix into tiles (e.g., 128x128) and clusters (e.g., 1x1 for simplicity). This matches the GPU's warp and block scheduling, reducing memory access overhead.
- Persistent Kernels: The code sets persistent=True, meaning the kernel stays resident on the GPU, minimizing launch overhead for repeated calls.
- Major Orders and Layouts: It detects row-major vs. column-major tensors and optimizes accordingly, ensuring coalesced memory access.
Why leave it untuned? For starters, it kept things simple while I validated the replacement. Autotuning adds overhead on first run and can be finicky with compilation. But yeah, there's a lot of performance on the table next steps would include flipping to tuned=True and experimenting with fusions. It also has variants for activations (LinearActFunc) and de-activations (DActLinearFunc), which could fuse ops further though GeGLU is mess on this, but I started basic.
Moving things to `E4M3fn`
after getting the custom linear layers up and running in bf16, I was eager to push things further. The B200 GPUs are designed to absolutely dominate with lower precision formats like FP8, especially for inference workloads. FP8 can drastically reduce memory usage and boost throughput by leveraging the Blackwell tensor cores. I added native support for FP8 and even FP4 GEMMs. Since my setup was already using CuTe-based optimizations, integrating FP8 seemed like the next logical step to make Krea-Realtime.
I spent a few days experimenting with FP8 where it mattered most in the key GEMM operations within the Quack linear layers. Everything aligned perfectly on paper:
-
The DLPack specification (version 0.8 and up) explicitly defines types like kDLFloat8_e4m3fn = 10 and kDLFloat8_e5m2 = 12, along with even lower precision options like FP6 and FP4.
- CUTLASS and CuTe treat Float8E4M3FN and Float8E5M2 as first class citizens, exposing them natively.
- The DLPack header itself supports it kDLFloat8_e4m3fn = 10U, with a comment noting "float8_e4m3: type_code = 8, bits = 8, lanes = 1 (packed in memory)."
- The C++ _C._to_dlpack refuses to map torch.float8_e4m3fn to the corresponding DLDataType{code=10, bits=8, lanes=1}, even though the spec allows it.
Exploring custom attention masks
With the custom linear layers in place, I turned my attention (heh) to another key component of Krea-Realtime the attention masks used in its transformer architecture. Since this is an autoregressive video model, masks are crucial for controlling what parts of the input sequence the model can "see" during generation. They enforce causality to prevent future information from leaking into past predictions, which is essential for stable, coherent video outputs. But Krea-Realtime goes beyond a simple causal mask it uses a "block-causal" mask to handle long form generation while mitigating issues like error accumulation and distribution shifts.
From the model's design, Krea-Realtime employs a block-causal mask during both pretraining and inference, particularly in the causal ODE pretraining phase and KV cache recomputation. The sequence is divided into blocks, where each block consists of multiple frames (e.g 3 frames per block). Within a block, attention is fully bidirectional all tokens (representing latent frames) can attend to each other freely. Between blocks, it's strictly causal later blocks can only attend to earlier ones, not vice versa. This allows for:
- Intra-Block Bidirectionality: Allows interactions within a small group of frames, improving local coherence without breaking overall causality.
- Inter-Block Causality: Ensures the model generates frames sequentially, attending only to past context, which is vital for autoregressive tasks like video generation.
- KV Cache Recomputation: To handle long videos and avoid error buildup, the model uses a sliding window of frames. When evicting old frames from the KV cache, it recomputes the cache for the remaining frames using this block causal mask. This "breaks the receptive field" of outdated KVs, preventing error propagation, and also enables re-encoding the first frame to fix distribution shifts.
So I implemented and tested several custom attention mask variants using Flex Attention. I generated masks for typical Krea setups 1560 tokens per frame, and 3 frames per block. I added options for local attention windows (local_attn_size) to limit scope and potentially speed things up, plus a causal flag for easy switching.
None of these ultimately outperformed the original block-causal mask in terms of generation stability and quality they either introduced artifacts, reduced coherence, or didn't save enough compute to justify the drop. But experimenting was worthwhile for understanding the trade-offs. Here's a breakdown of the key variants I tried:
Pure Causal Mask
def attention_mask(b, h, q_idx, kv_idx):
return kv_idx <= q_idx
Local Causal Mask
def attention_mask(b, h, q_idx, kv_idx):
max_dist = local_attn_size * frame_seqlen
return (kv_idx <= q_idx) & (q_idx - kv_idx < max_dist)

Intra-Block Causal Mask
def attention_mask(b, h, q_idx, kv_idx):
block_size = frame_seqlen * num_frame_per_block
block_start = (q_idx // block_size) * block_size
return (kv_idx >= block_start) & (kv_idx <= q_idx)

Block-Diagonal Non-Causal Mask (with Optional Local Window)
def attention_mask(b, h, q_idx, kv_idx):
ends = torch.zeros(full_len, device=device, dtype=torch.long)
frame_indices = torch.arange(0, total_length, frame_seqlen * num_frame_per_block, device=device)
for tmp in frame_indices:
ends[tmp:tmp + frame_seqlen * num_frame_per_block] = tmp + frame_seqlen * num_frame_per_block
if local_attn_size == -1:
return (kv_idx < ends[q_idx]) | (q_idx == kv_idx)
else:
return ((kv_idx < ends[q_idx]) & (kv_idx >= ends[q_idx] - local_attn_size * frame_seqlen)) | (q_idx == kv_idx)
I could not find the video for this though here are some that I forgot to document but the results are interesting.

And then underlying the obvious I tried the full bidirectional Attention which worked pretty good probably better then the origional mask but I could just be me but anyways the tradeoff was not that exciting these customs were fun to tinker with and taught me a lot about mask impacts, but the original block-causal remains the best for Krea-Realtime's balance of stability and performance (I mean it was trainied on it so...). If I revisit, maybe hybrid masks with dynamic block sizes could bridge the gap. For now, back to the drawing board on other optimizations!


Ditching Flex-Attention for FlashAttention4
With the custom masks experimented with but ultimately sticking close to the original block-causal design, the next big bottleneck was the attention mechanism itself. Krea-Realtime relies on Flex Attention for its block-sparse masking needs, but Flex Attention isn't particularly optimized specially not for B200s. It's flexible (hence the name), but that comes at a cost in raw performance compared to kernels like Flash Attention 4 or Sage Attention switching to FA4 seemed like a no brainer to boost throughput without sacrificing accuracy I mean it does use approximations for softmax so a little degradation is inevitable but nothing that can be observed without proper evals.
The challenge was adapting FA4 to support our block-causal mask, since FA4 natively handles causal or local windows but not arbitrary block sparsity out of the box. FA4's forward pass (_flash_attn_fwd) allows a score_mod callable a hook to modify attention scores before softmax. This is gold for custom masking instead of a static mask tensor (which would be memory-hungry for long sequences), I defined a JIT score modifier that applies the block-causal logic dynamically.
@cute.jit
def block_causal_score_mod(score, b, h, q_idx, kv_idx, *, aux_tensors=None):
ends = aux_tensors[0] # Int32[full_seq_len]
q = q_idx[0]
allowed = (kv_idx < ends[q]) | (kv_idx == q)
# typed -inf, not elegant and I hate it but I was done matching the cute dtype
neg_inf = score - score - 1e6
return cute.where(allowed, score, neg_inf)
def compute_ends_tensor(num_frames, frame_seqlen, num_frame_per_block, device):
total_tokens = num_frames * frame_seqlen
padded_total = math.ceil(total_tokens / 128) * 128
full_len = padded_total
block_size = frame_seqlen * num_frame_per_block
num_blocks = math.ceil(num_frames / num_frame_per_block)
ends = torch.zeros(full_len, dtype=torch.int32, device=device)
block_starts = torch.arange(0, num_blocks * block_size, block_size, device=device)
block_ends = torch.clamp(block_starts + block_size, max=total_tokens)
block_ids = torch.clamp(torch.arange(full_len, device=device) // block_size, 0, num_blocks - 1)
ends[:total_tokens] = block_ends[block_ids[:total_tokens]]
ends[total_tokens:] = full_len # padded region
return ends
# ... RoPE and KV cache update code ...
q_fa = roped_query.contiguous()
k_fa = kv_cache["k"][:, :local_end_index].contiguous()
v_fa = kv_cache["v"][:, :local_end_index].contiguous()
if self.local_attn_size == -1:
window_frames = self.num_frame_per_block
else:
window_frames = self.local_attn_size
# Call official FA4
o_fa, _ = _flash_attn_fwd(
q=q_fa,
k=k_fa,
v=v_fa,
softmax_scale=1.0 / (self.head_dim ** 0.5),
causal=False, # score_mod handles masking
score_mod=block_causal_score_mod,
aux_tensors=[self.ends_tensor.to(q_fa.device)],
return_lse=False,
)
x = o_fa
# ... update cache indices ...
I see so much perf that I give up on nsys. I'll upload the nsys profile somewhere and link it here.


With some changes like enabling autotuning, adjusting block sizes (m_block_size, n_block_size), or even integrating split-KV I believe I can bring it down to a respectable number. The CuTe integration allows for that flexibility, and ongoing work in the FlashAttention repo (e.g., Blackwell-specific fixes) should help. Plus, combining this with FP8 (once the DLPack issue is sorted) could be explosive. Code to everything talked in this blog lives here BlackWan
I'm not good at prompting but here is V2V with all the above mentioned tricks and optimizations.


Profile insights on warmup
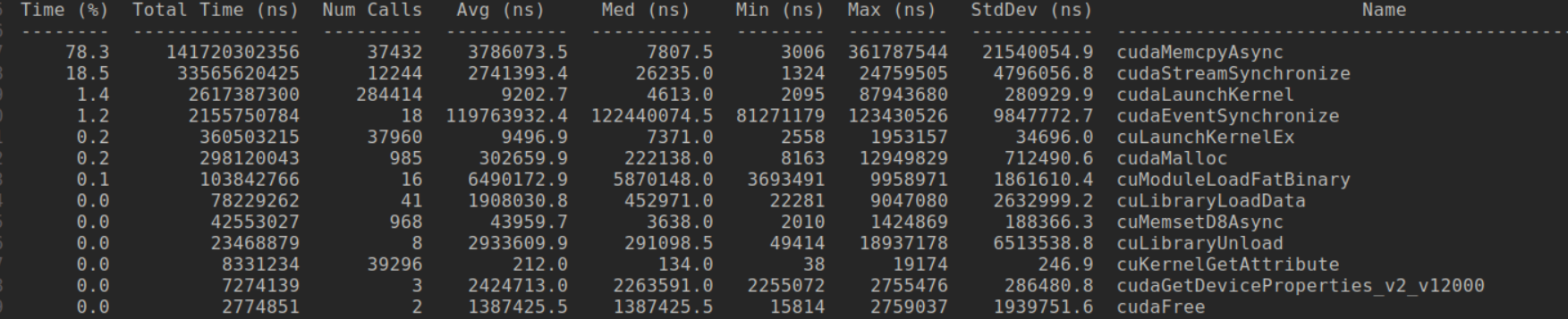
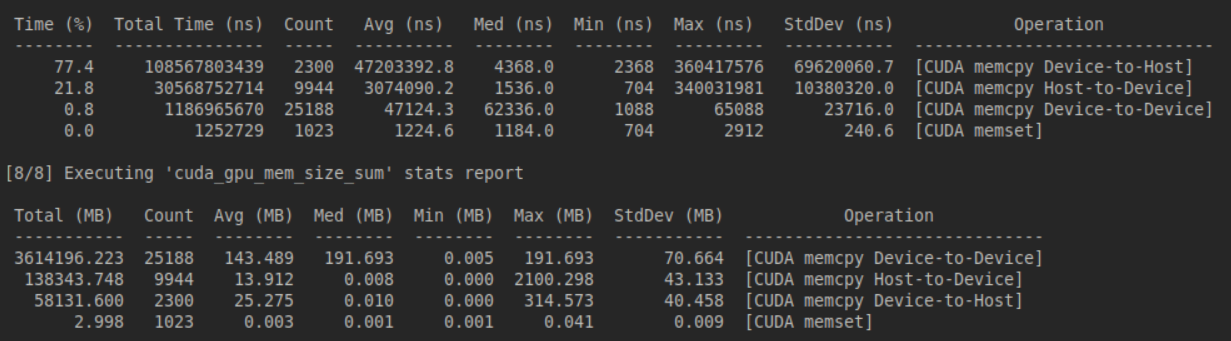
The denoising_loop dominates at 41%, which makes sense for an autoregressive video model it's the core sampling loop. Transformer steps (0-4) eat up another ~30% combined, with recompute_kv_cache at 16% highlighting the cost of our block-causal KV recomputation. VAE decode is minor (1.4%), but text encoding is quick.


Next Steps Part-2
I've made solid progress with custom linears, FP8 experiments, mask tweaks, and FA4 integration, but there's still plenty of low-hanging fruit (and some tougher nuts) to crack for ultimate performance. Here's my roadmap for the coming weeks.PyTorch Compile/Inductor now supports targeting NVIDIA's Python CuTeDSL (alongside Triton), enabling up to 2x faster Flex Attention compared to Triton-based implementations. This is huge for Krea-Realtime, since Flex Attention is our fallback for complex block-sparse masks.
Speaking of FA4, the ecosystem is catching up nicely. Flex-Attn has now integrated FA4 in source builds (PyTorch PR #167040), which could simplify my setup no more manual hooking if it handles block-causal natively. Even better, the Flash-Attention repo has a PR (#1985) adding block-sparse support for SM100: It implements block-sparse in flash_fwd_sm100.py, updates interface.py for SM100 block calcs (with a 2x multiplier on m_block_size since one CTA handles 2*tile_m rows), adds mask_mod in mask.py for sparse masking. I'll build from source and test this potentially replacing my custom score_mod with their optimized block-sparse path.
My UntunedQuackLinear was a great start, but as the name implies, it's untuned leaving perf on the table. Next, I'll enable tuning in the GEMM kernels (tuned=True in linear_func), benchmarking different tile/cluster shapes for Krea's specific MLP dims (5120→13824→5120). CuTe's autotuning should help here.
I'll also tweak the underlying gemm wrapper: experimenting with pingpong=True for better overlap, larger max_swizzle_size, or varlen args if sequences vary. Not super optimistic GEMMs are already pretty optimized I'll profile before/after to quantify.
For real-time video gen, I need to hit at least 16 frames/sec with streaming enabled. Single GPU is fine for prototyping, but tensor parallelism (TP) across 2-4 B200s should get me there distributing model layers or attention heads. I'll start with 2x B200s, sharding the transformer. Streaming means generating frames on-the-fly with KV cache, so low-latency TP is key. If needed, bump to 4x for more parallelism, hitting my 16 fps target for longer clips.
To guide all this, more profiling is essential. I'll ramp up my NSys runs for timeline traces, spotting bottlenecks in CuTe kernels. Also, dive into PTX disassembly to understand register usage, occupancy, and SM100-specific ops maybe hand-tweak if autotuning falls short.
Then onto making it a little lossy with H2-Cache, I'm leaving this for last since this won't be fair while I write about optimizations and add a caching technique in the mix.